Swarmpit (à ne pas confondre avec Brad Pitt …) est une interface Web légère et relativement intuitive permettant de gérer un cluster Docker Swarm.
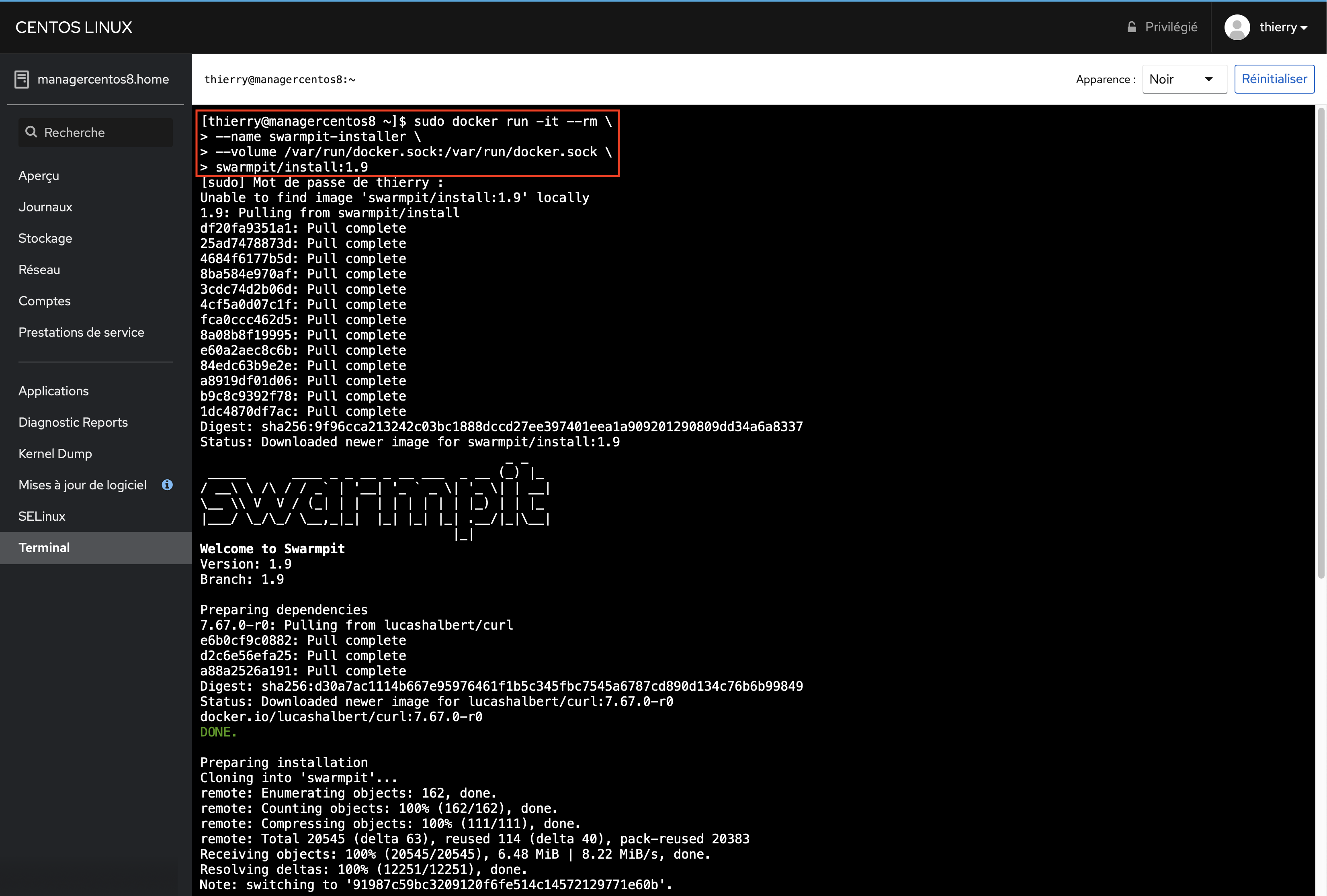
L’installation de Swarmpit est relativement simple: on va se connecter sur le manager de notre cluster Docker Swarm et nous allons exécuter la commande ci-dessous:
sudo docker run -it --rm \ --name swarmpit-installer \ --volume /var/run/docker.sock:/var/run/docker.sock \ swarmpit/install:1.9
Nous pouvons maintenant nous connecter sur le tableau de bord Swarmpit via l’URL suivante:
http://managercentos8:888
Déploiement d’un service
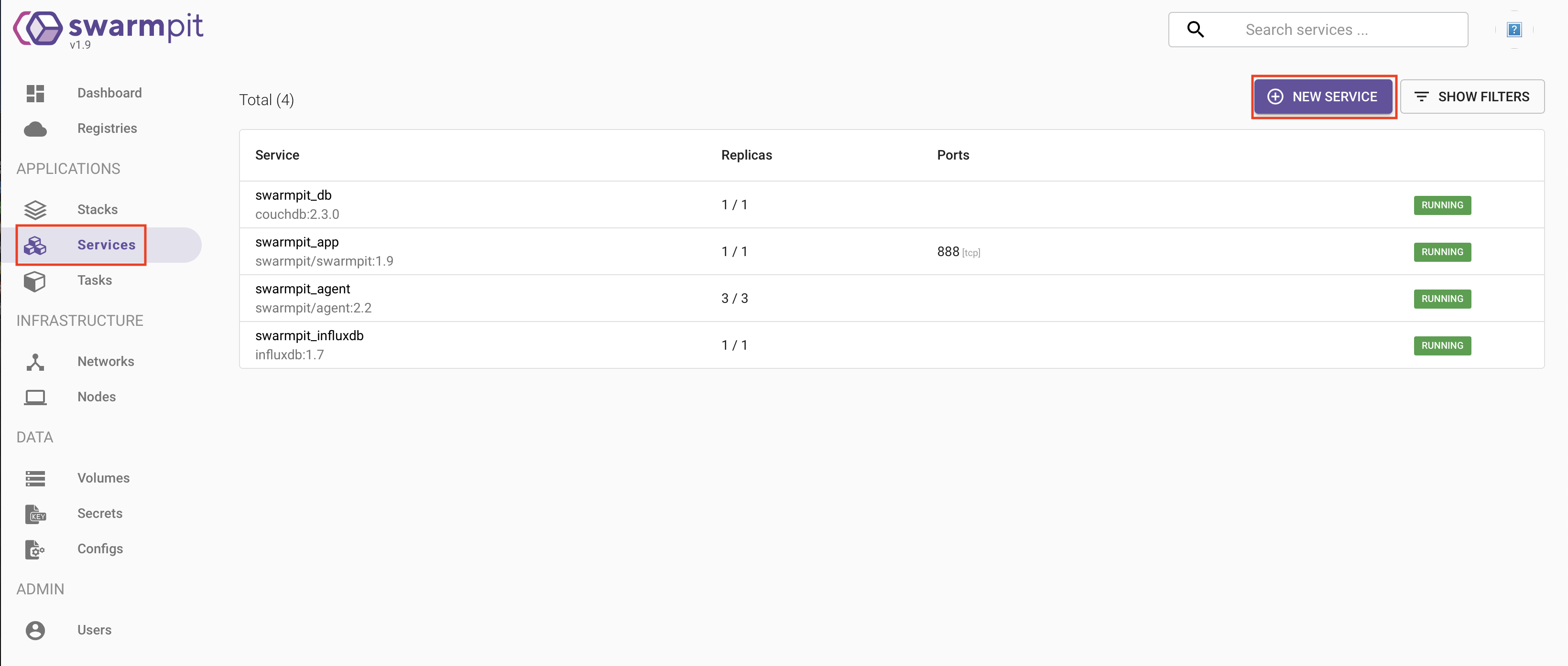
Nous allons déployer un service tout simple qui va nous permettre de vérifier que notre Swarm fonctionne correctement.
Dans le menu « Services », nous allons donc cliquer sur « New service »:
Ensuite, nous allons rechercher l’image « topmonks/docker-napp » dans le « repository » public:
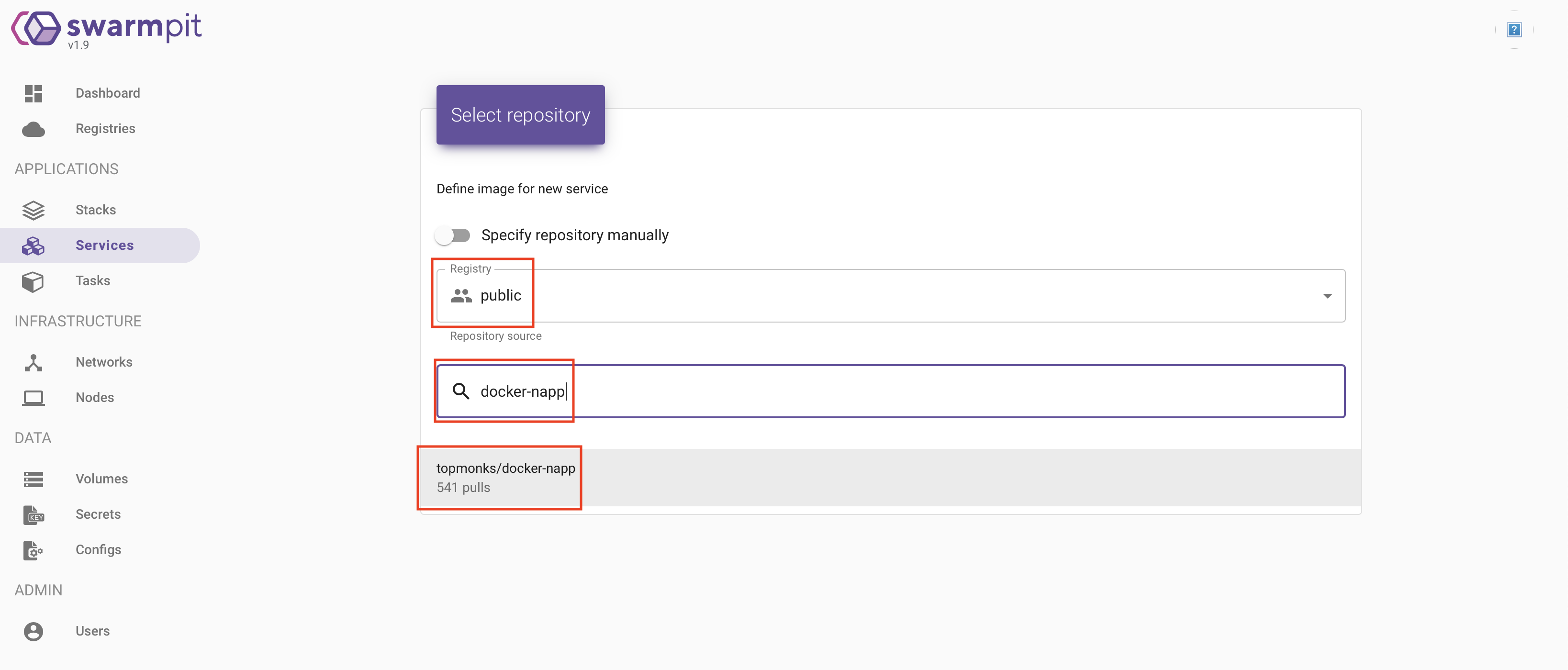
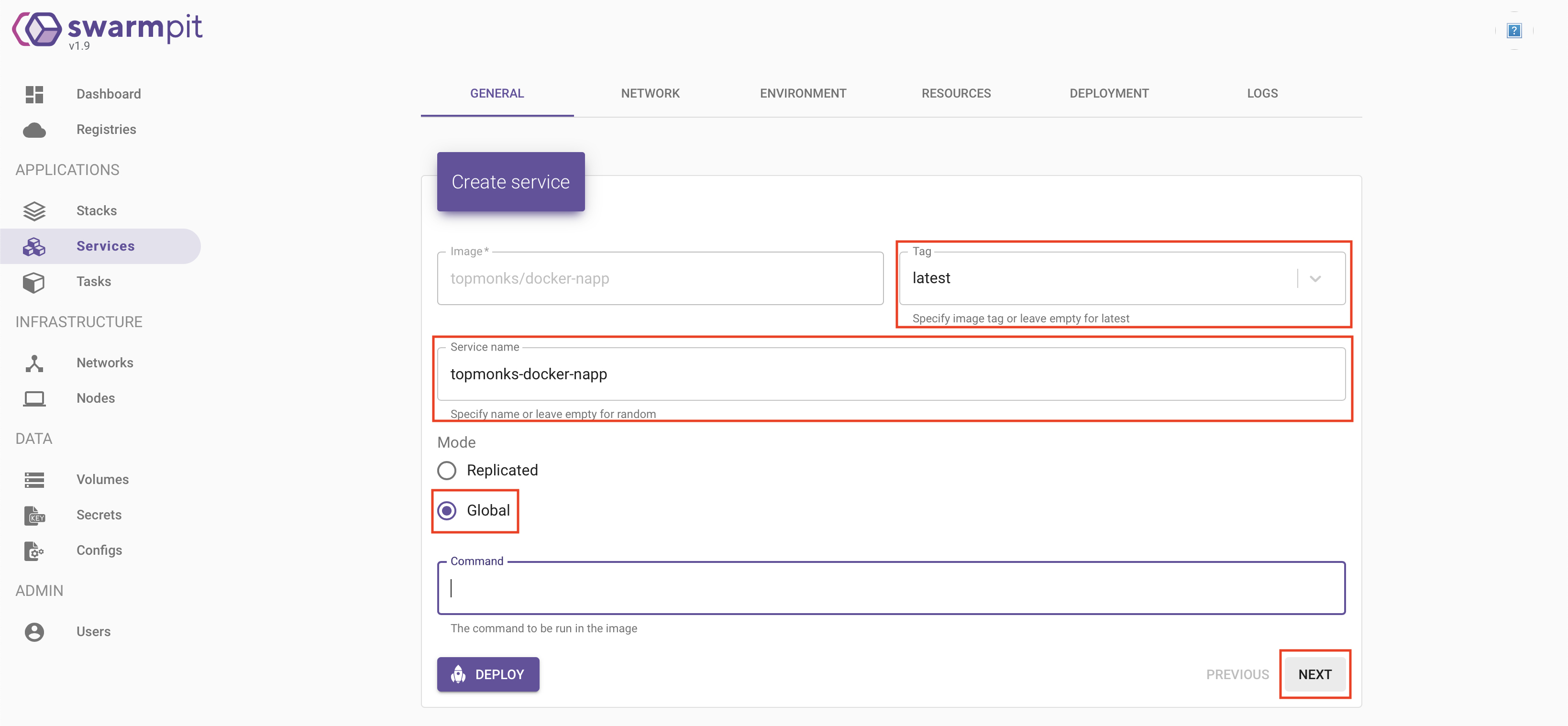
Sur la page suivante, nous allons définir quelle version de l’image utiliser. La dernière version semble la plus indiquer. Nous allons donc choisir « latest ».
Pour le nom du service, vous avez la possibilité de ne pas le renseigner et un nom aléatoire sera attribué au service. Pour ma part, je préfère le renseigner avec un nom intelligible.
Nous allons ensuite choisir le mode de déploiement:
– « global »: un service va être mis en place sur chaque noeud du cluster
– « replicated » : permet d’obtenir plusieurs instances d’un même service sur un même noeud
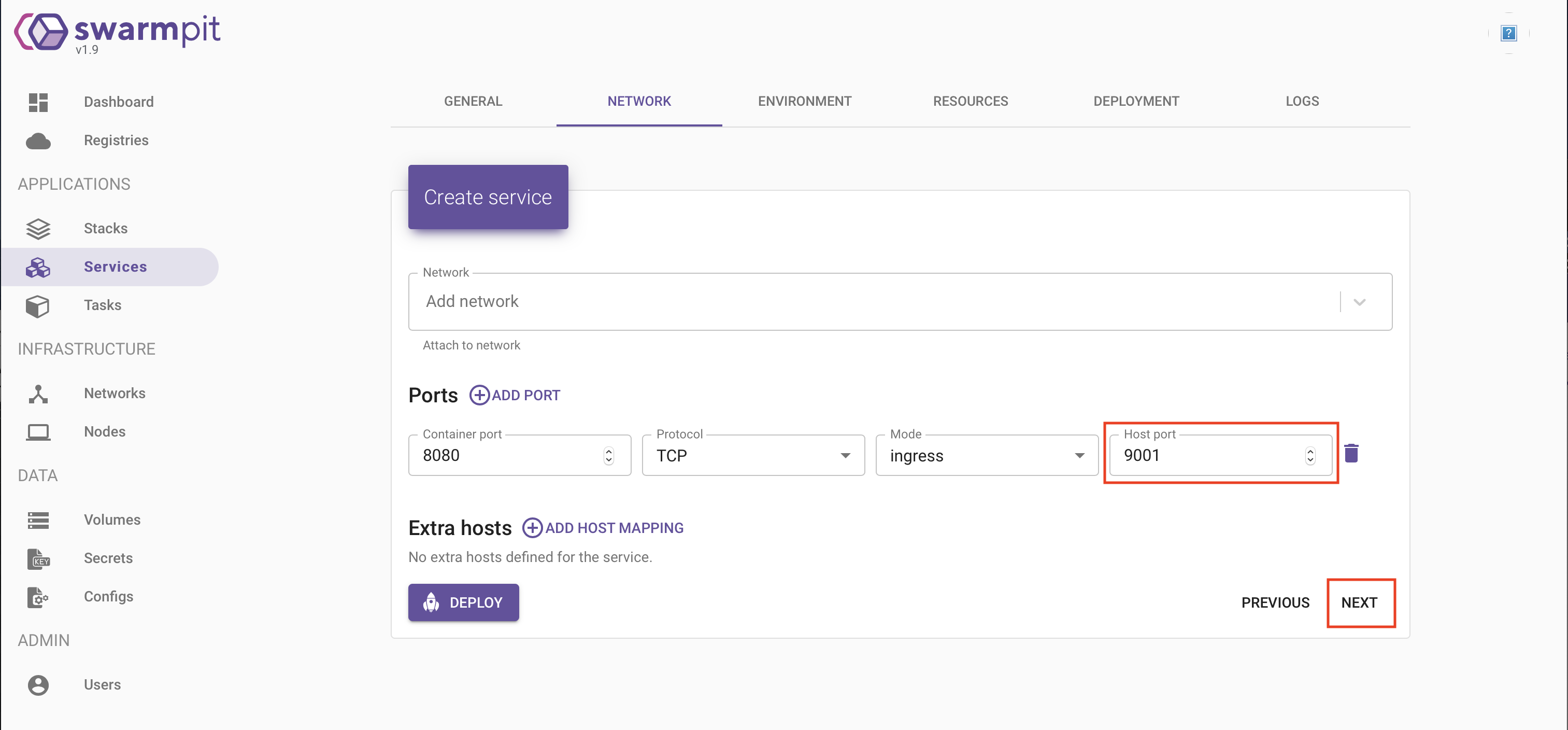
L’étape suivante va consister à définir les paramètres réseau de notre service: nous allons exporter le port 8080 de notre container au travers du port 9001:
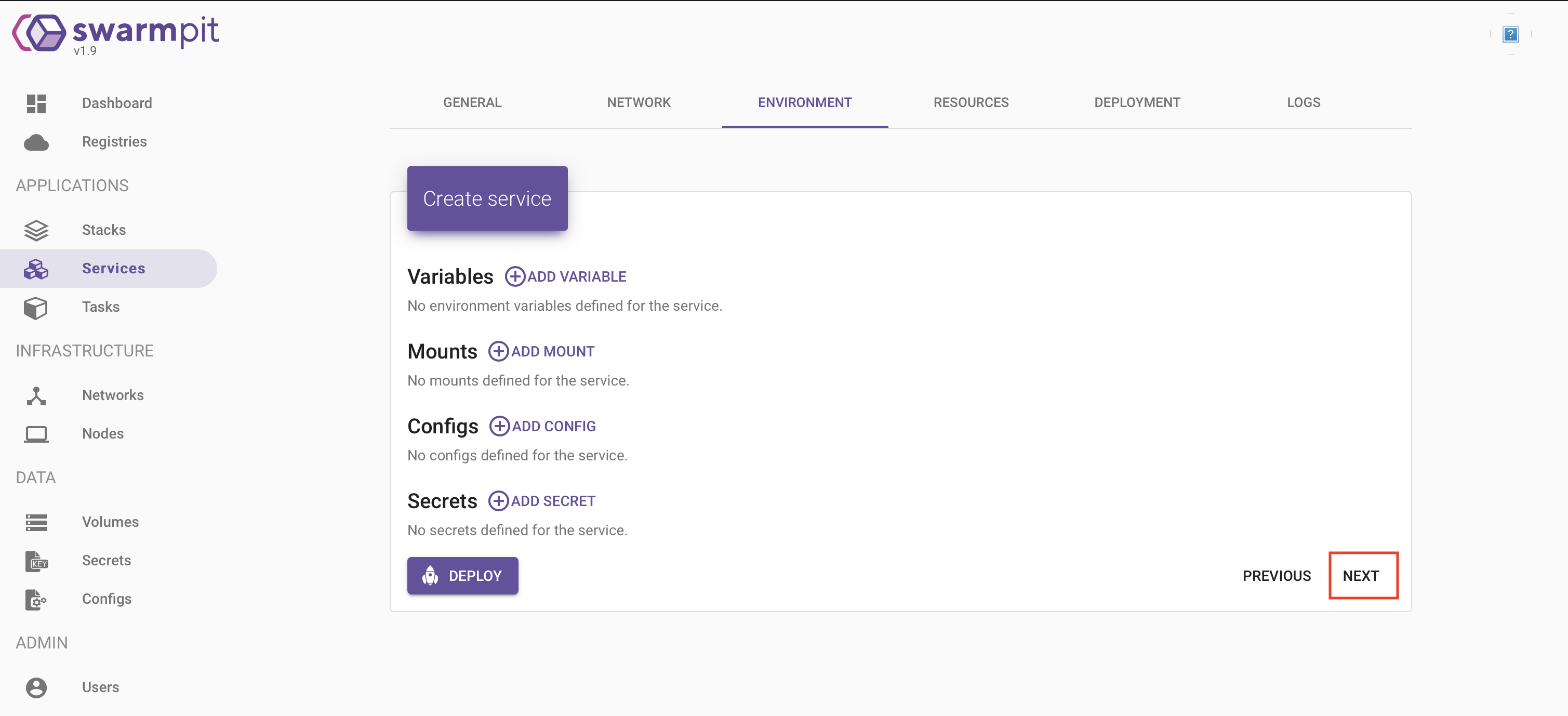
On peut ensuite configurer divers éléments très importants mais qui ne sont d’aucun intérêt pour ce container:
– des variables d’environnement
– des points de montage
– des configurations
– des secrets
Nous allons ensuite définir les ressources processeur et mémoire nécessaires à l’exécution du service. Dans notre cas, nous allons tout laisser par défaut:
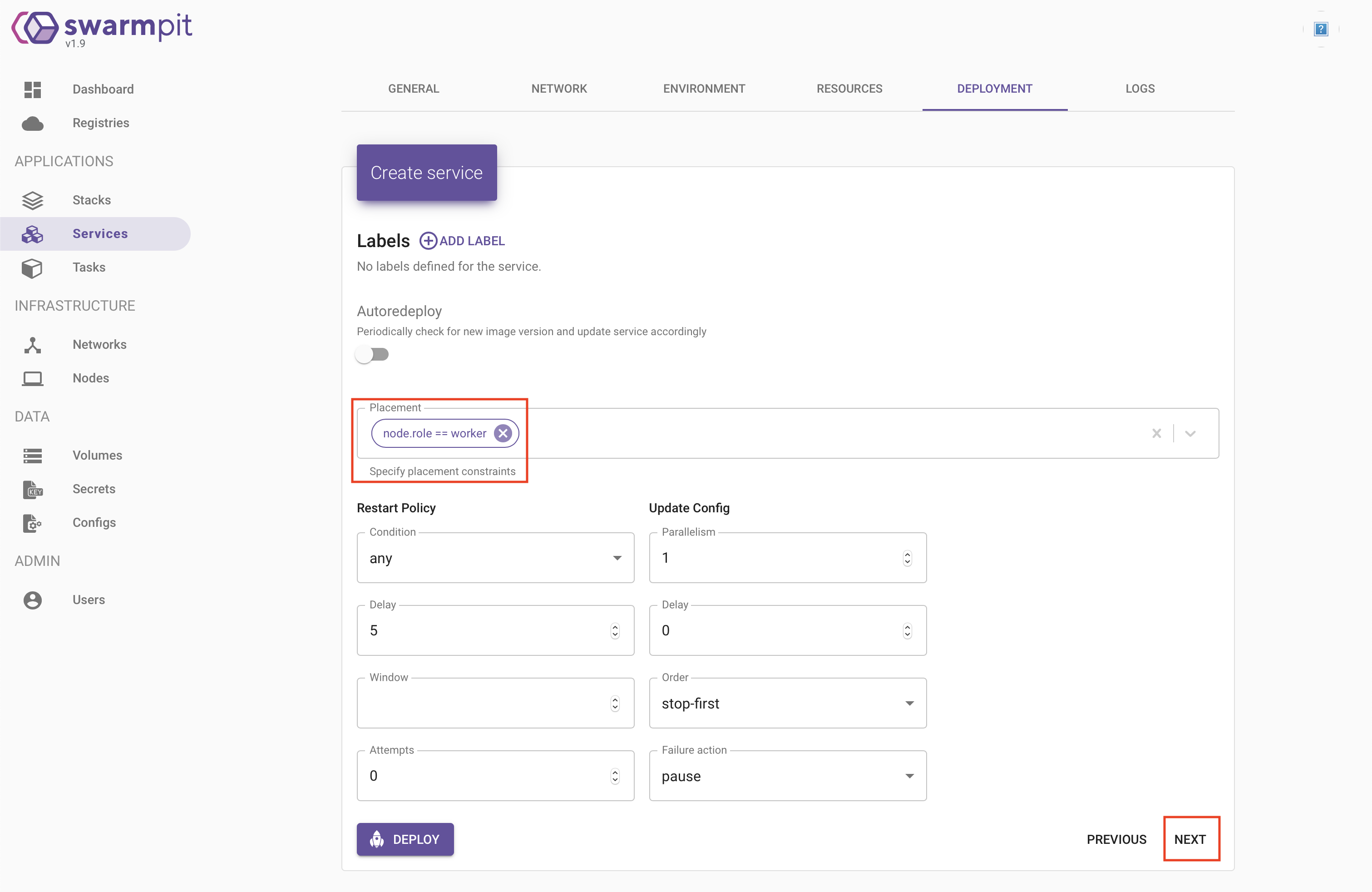
La page suivante va nous permettre d’ajouter des « labels » à notre service et surtout de définir la stratégie de déploiement.
Dans mon cas, j’ai choisir de déployer le service uniquement sur des noeuds de type « worker ». Cela se traduit donc par la contrainte : « node.role == worker ».
Enfin, nous allons définir la méthode de log du service en laissant les paramètres par défaut:
Le service va alors se déployer sur les 2 noeuds.
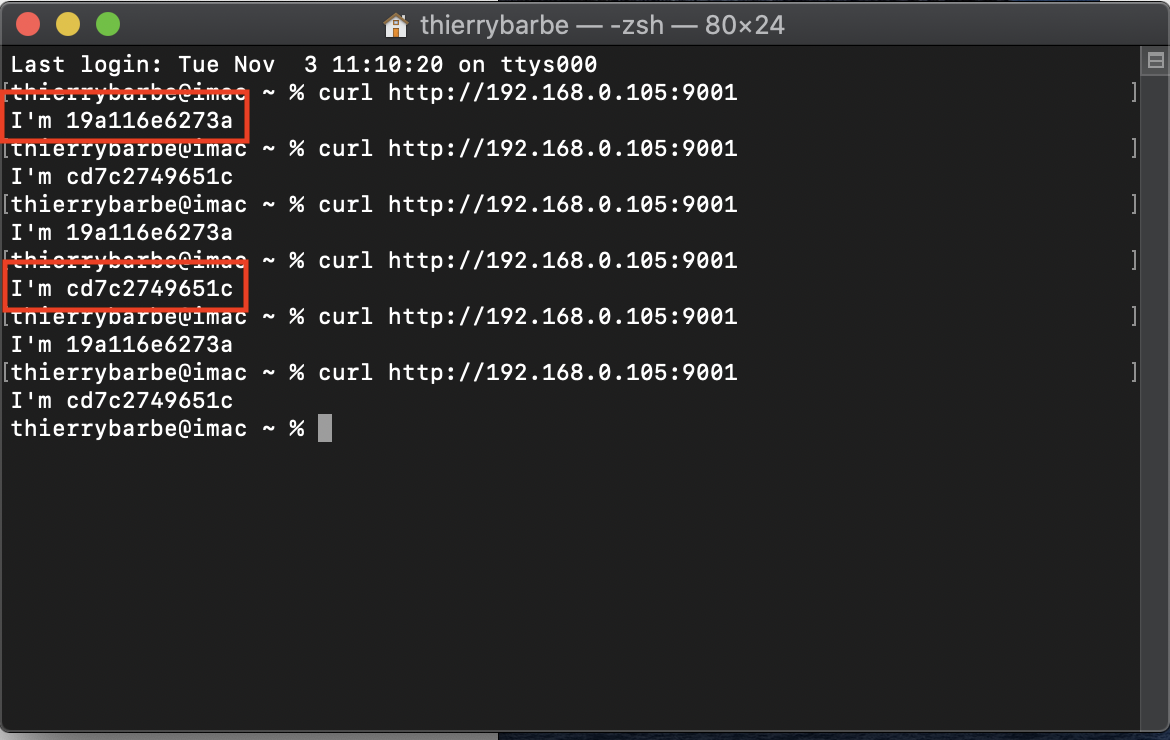
Nous allons maintenant tester la distribution des requêtes au sein de notre cluster en appelant plusieurs fois le service (192.168.0.105 est l’adresse IP du manager :
curl http://192.168.0.105:9001
On voit bien ci-dessous que les appels du service sont traités indifféremment par les 2 noeuds du cluster. Well done!